
This article—adapted from a talk I gave at GraphQL Conf. 2021—describes how Salsify's GraphQL environment creates a productive, enjoyable, and cohesive developer experience from the backend to the frontend.
Motivation
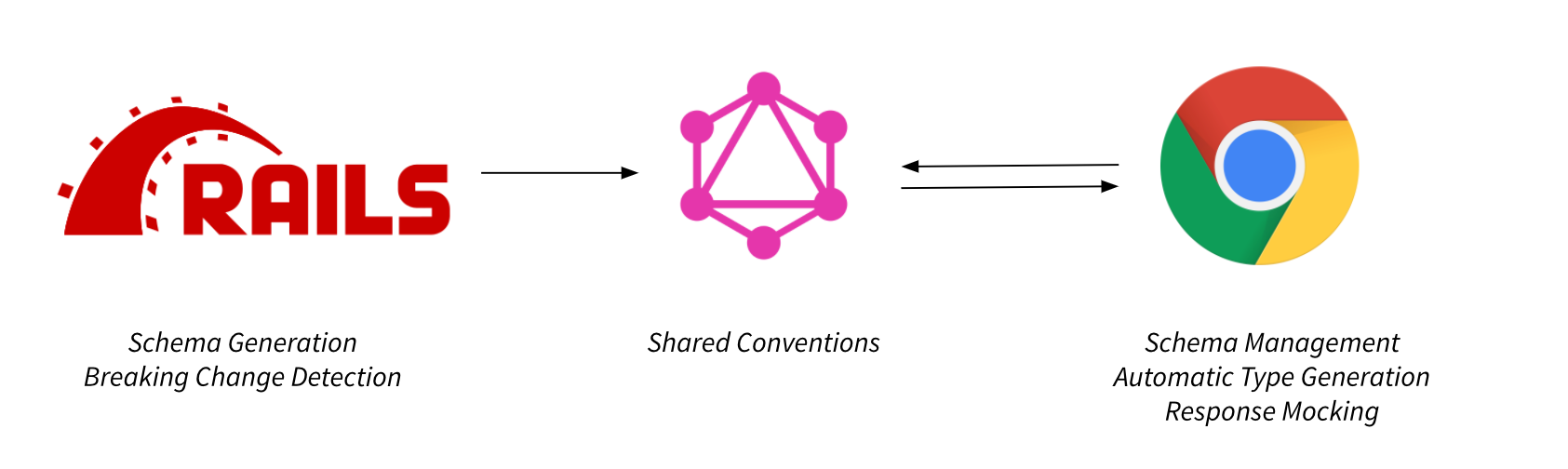
GraphQL has become one of my favorite technologies to use across the full stack of development at Salsify, so I would like to take you through some of the tooling supercharging development at Salsify. We will explore how automated schema generation and breaking change detection make building and evolving backend GraphQL services a breeze while automated type generation and response mocking help us consume those APIs on the frontend.
Like many technologies, GraphQL is only as good as its surrounding ecosystem. GraphQL’s ability to reduce the friction between the server and client is one of its core strengths, so I’d like to demonstrate tooling playing to this strength of removing friction and show how GraphQL is uniquely positioned to enable it. When put together, these tools make for an incredibly delightful and productive developer experience, so I hope to leave you with some ideas for how you can take your GraphQL experience to the next level.
Conventions
The foundation of Salsify’s GraphQL tooling is our shared conventions and guidelines that work to define what an idiomatic Salsify GraphQL schema looks like. These shared conventions not only make it easier to introduce new GraphQL types in a consistent fashion that avoids wasted time from rehashed discussions and duplicated code, but they also allow us to build convention-aware tooling. This convention-aware tooling helps avoid confusing, non-standard usage that might slow down consumers of the API or other developers at Salsify by flagging convention violations before the code ever leaves the developer’s machine. Additionally, conventions speed up development as we can factor out common patterns to reduce boilerplate.
|
We have developed a large set of GraphQL conventions at Salsify and continue to add new ones, so there a too many to discuss each one individually, but here are a few examples. For one, we have a convention around how pagination should work. This includes how we name paginated types and the mechanics of the pagination. Additionally, we have conventions around how we expose the ability for clients to filter a collection of elements. These conventions manifest as a standardized filtering language. Along with filtering, we have conventions describing how to apply ordering to sorted fields in our graph. Lastly, to avoid naming collisions around generic or common terms, we’ve developed a namespacing convention that helps tie types and fields to specific areas of our application. For example, we namespace the types related to our application’s security by ensuring they have the “security” prefix. |
Pagination: “Paginated types are always named with the base type's name postfixed with Filtering: “Fields wishing to implement advanced, composable filters will accept the argument Ordering: “Fields wishing to implement ordering will accept the argument Namespacing: “We should prefix types specific to a certain user-visible concept of the application (e.g., workflow or security) with a consistent name” |
Establishing Conventions: When & How
Before moving on from this discussion of conventions, I would like to touch on when in your GraphQL adoption lifecycle you should think about adopting conventions and how you can start to develop and manage them. For the “when”, it is a tradeoff between having enough real-world usage on one hand and not wanting to delay too long to avoid building a large backlog of debt on the other. That said, developing your conventions upfront will generally be best to help ensure a consistent API.
Furthermore, new scenarios will always emerge that your current set of conventions does not handle. Being proactive and establishing conventions for these emergent cases is also critical. Developing small working groups to explore and prototype different solutions has proven to be an effective way to handle particularly complex scenarios.
In terms of the “how”, at Salsify, we store our conventions in a GitHub repository so changes go through a Pull Request process where any engineer can comment and flag concerns or propose alternatives. It is also important to build an engaged internal GraphQL community within your organization where different teams and their use cases are represented. A GitHub group to tag in Pull Requests and Slack channel for discussion and sharing can be useful ways to foster an engaged community.
Schema Generation
At Salsify, we never write in the GraphQL schema definition language, or SDL, by hand as the SDL lacks the ergonomics a schema author might want. To foster a better authoring experience, we use a Ruby DSL to generate the final GraphQL schema. Our Ruby DSL is a wrapper around an open source gem, graphql-ruby. We have extended the gem to incorporate the previously mentioned conventions. Since Ruby is a language Salsify’s engineers are already comfortable with, the DSL makes it easy to introduce new types to the schema or quickly define a proof-of-concept to share with others. The DSL makes it easier for developers who may be unfamiliar with GraphQL to quickly ramp up and start contributing as they do not have to learn the GraphQL SDL to get started.
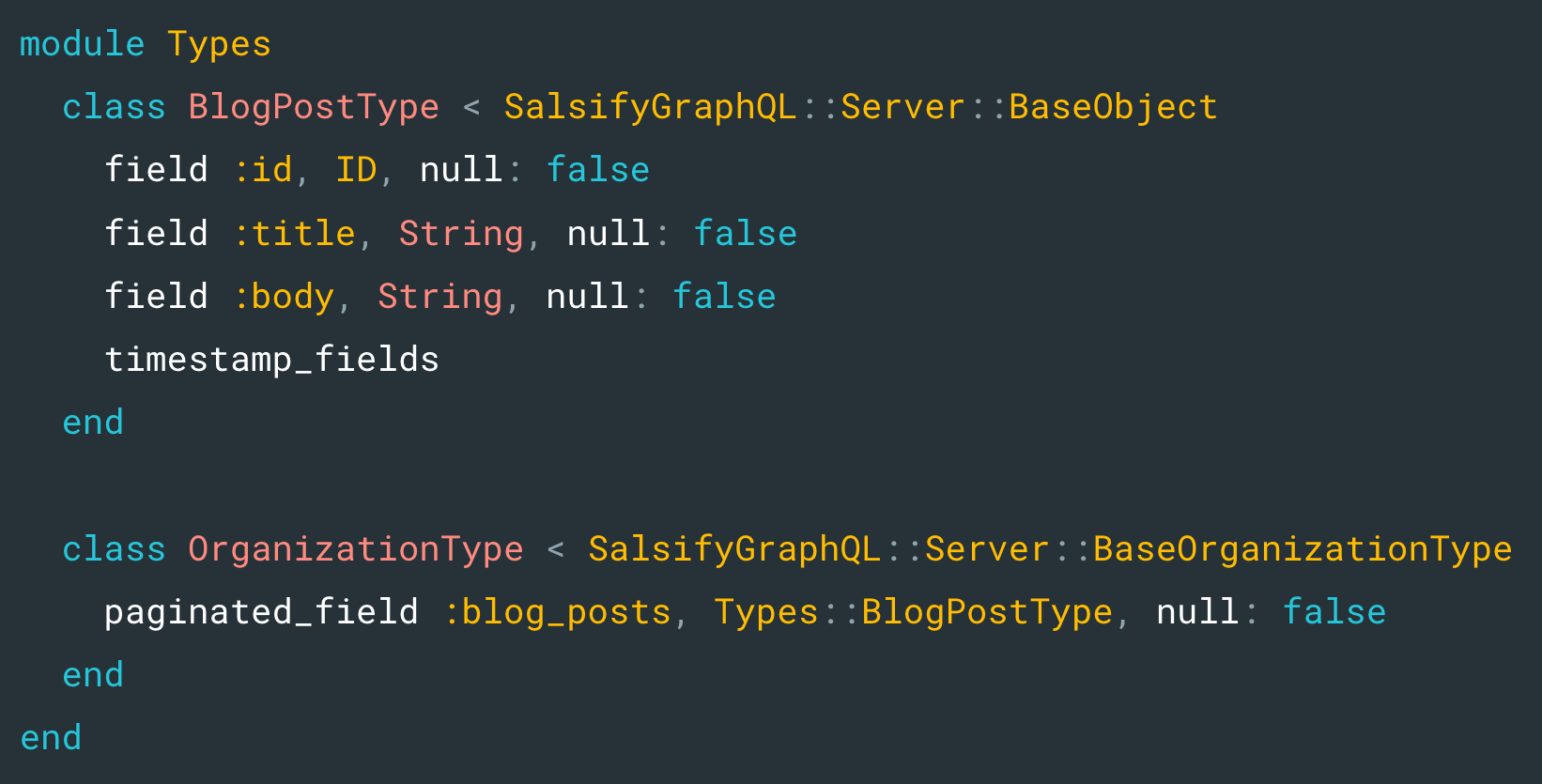

Furthermore, as I mentioned earlier, a major benefit of our convention-aware schema generation is boilerplate reduction. For example, in the sample above, we have a paginated_field :blog_posts line which will generate all the auxiliary pagination types needed to adhere to our pagination conventions as well as the runtime logic to power those pagination types.
This ability to avoid having to manually type out repeated patterns is one of the major benefits of the Ruby DSL as the GraphQL SDL is not optimized for authoring and requires burdensome duplication. For example, an interface in the SDL requires you duplicate fields between the interface and implementing types resulting in duplicate code. The following example of a helper for representing asynchronous operations demonstrates this.

Ruby DSL |
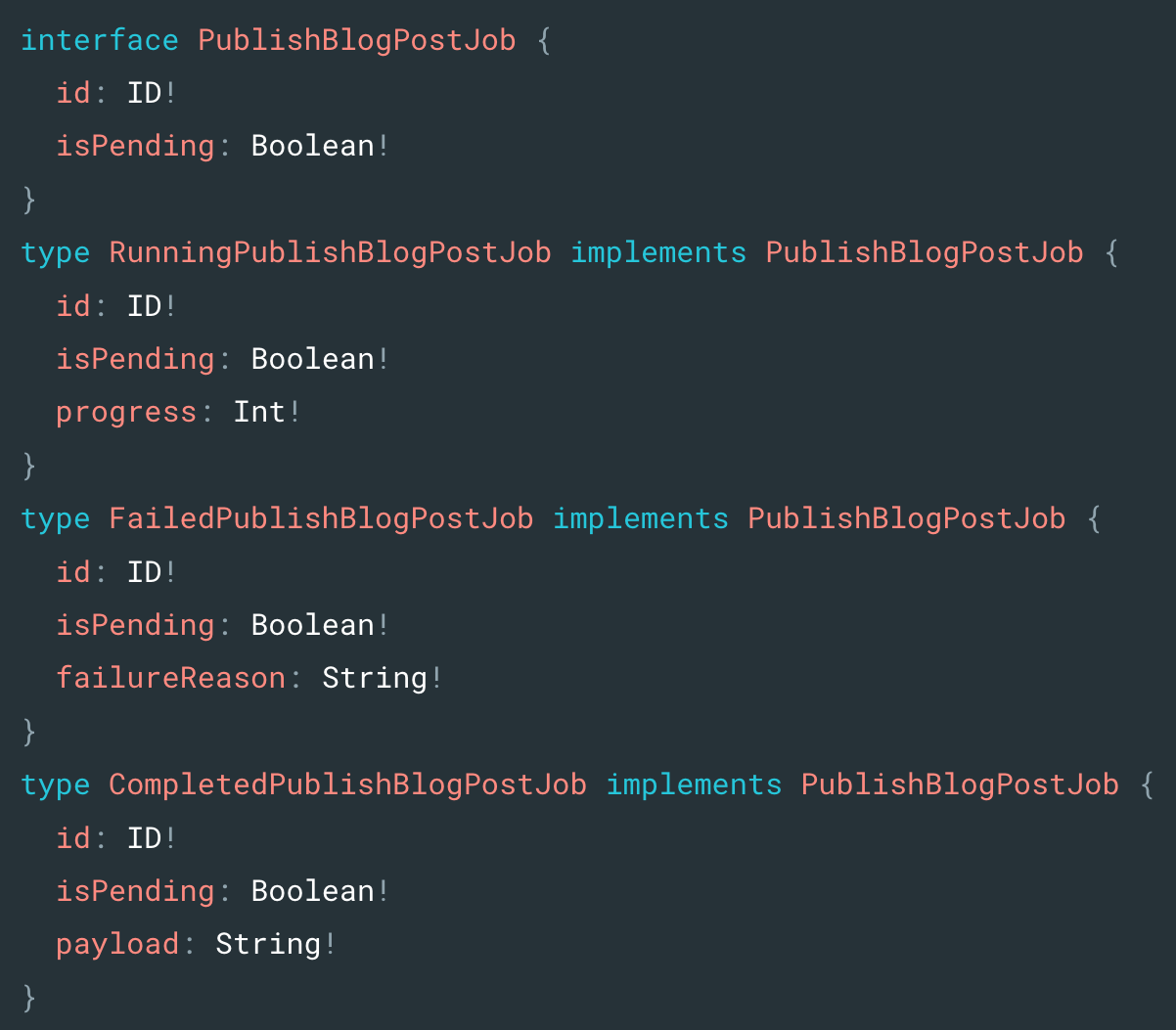
 Generated SDL
|
:running state that indicates some amount of progress which is reflected by the RunningPublishBlogPostJob type in the SDL. Next, we have a terminal :failed state that reports its failure reason. Lastly a terminal :completed state that contains the resulting payload of the job. We see the benefits of our DSL as we did not need to repeat the share interface fields in the Ruby DSL like the SDL does.Type Generation
So far, we have seen how our tooling makes it easy for backend developers to flesh out a complex GraphQL schema with a few lines of Ruby. We will now take a look at some of the tooling that helps supercharge our frontend development starting with automated TypeScript type generation.
One major benefit of GraphQL is the type information the schema carries. We know the exact shape of the data based on the schema and the query we are making. More importantly, machines can understand this type information which we can leverage in our tooling. At Salsify, we have found the type information a GraphQL schema carries makes it a perfect companion for TypeScript as TypeScript allows us to make use of that type information in our JavaScript code. Good tooling is again critical here as the TypeScript types are worthless if they do not accurately reflect the GraphQL schema or the query we are making. For example, if we remove a field from our query but forget to remove it from the type definition, we lose many of the benefits of type checking. The solution is to automate the type generation to reduce the risk of human error.
We have written a buildGeneratesConfig helper as a wrapper around graphql-code-generator plugins to generate TypeScript types from our GraphQL documents. Our custom wrapper makes this type generation easy to setup, ensures we use standardized plugin configuration across different repositories, and allows us to incorporate our GraphQL conventions.
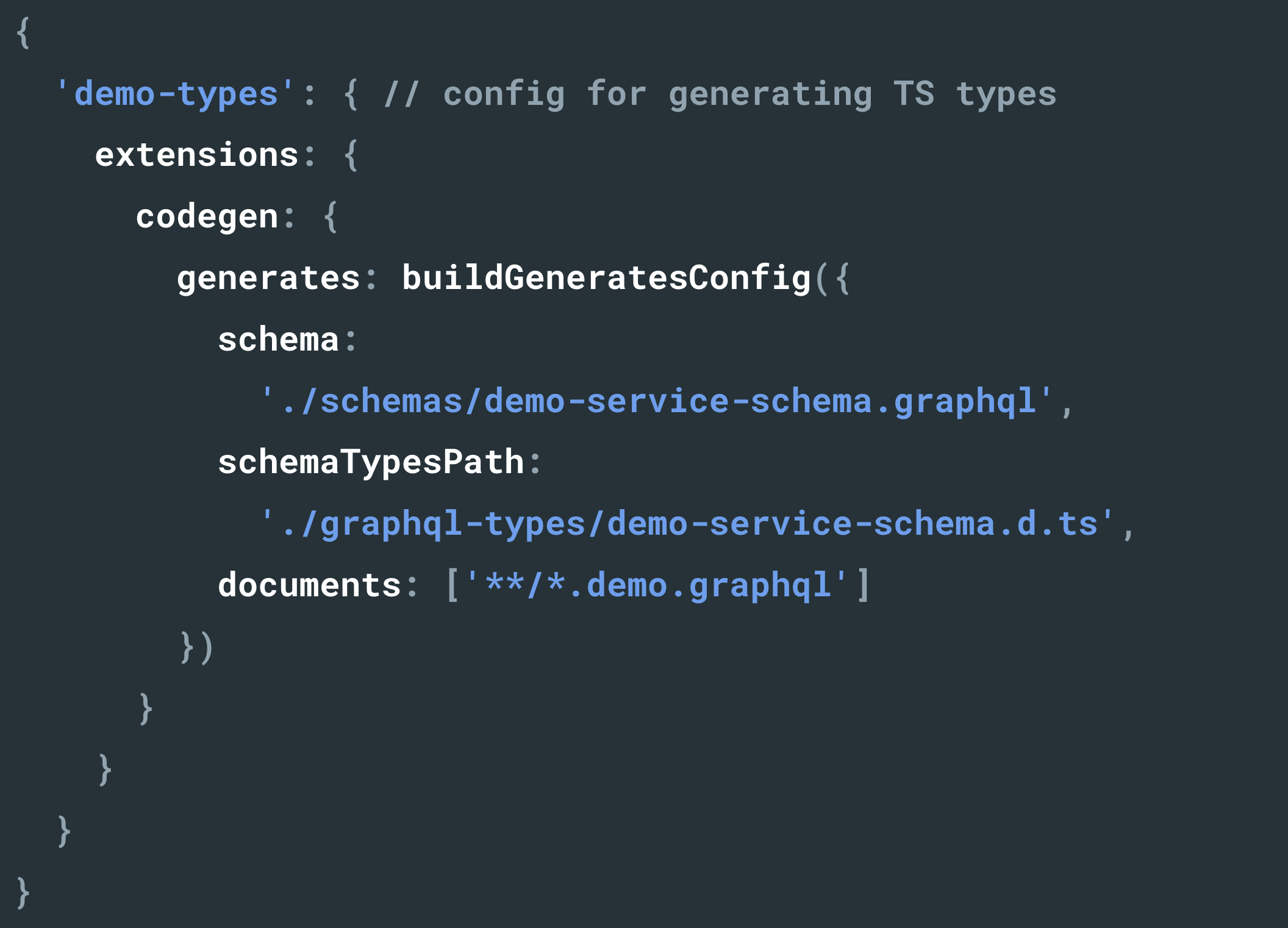

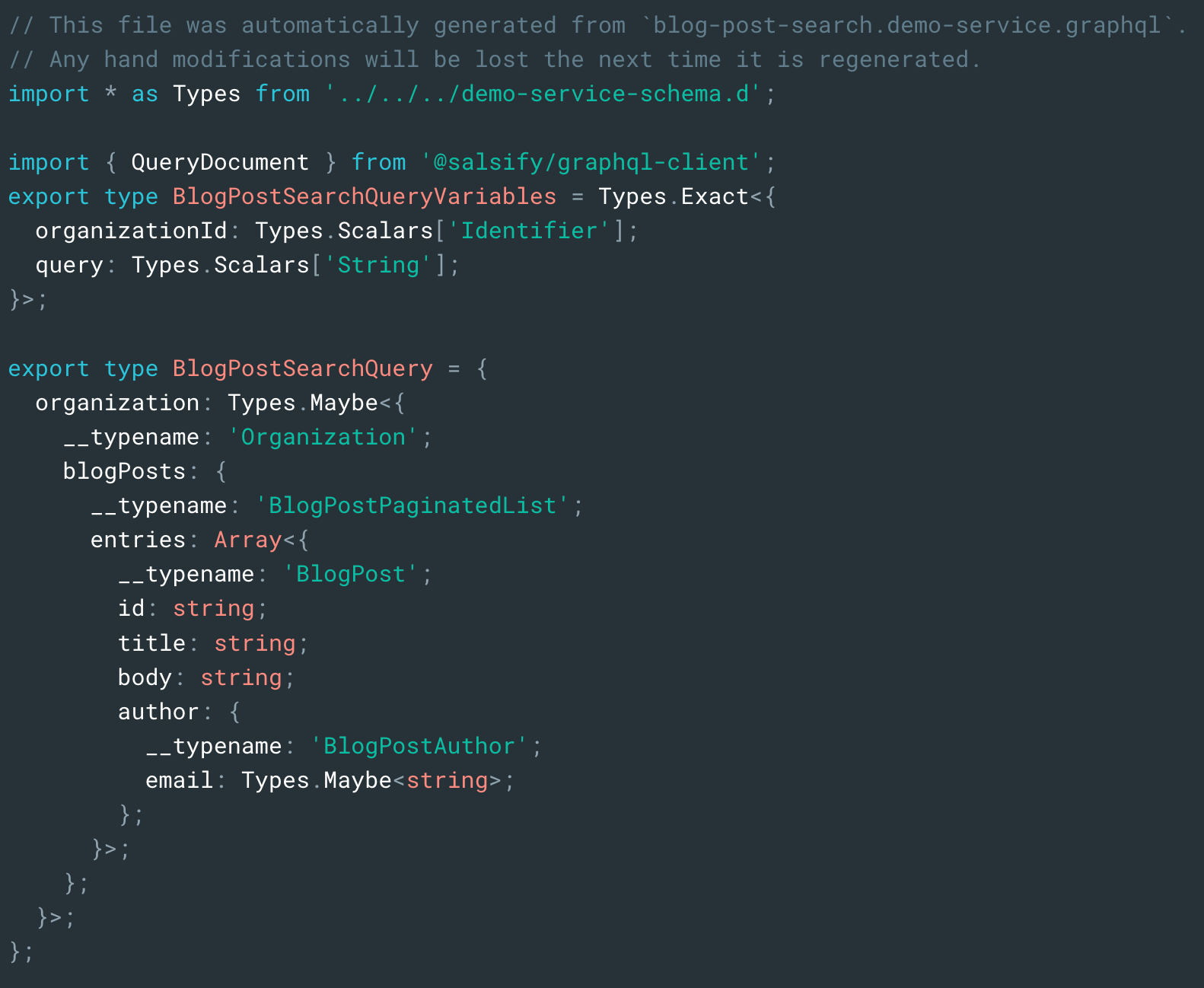

When a developer updates their query the corresponding TypeScript type automatically updates, and if that change breaks their code, the developer will instantly see the regression reflected as a type error. This feedback loop not only helps increase confidence in our code but also reduces risk when refactoring or extending code later on—all of which leads to a smoother developer experience with less time spent worrying about what will break when making a change.
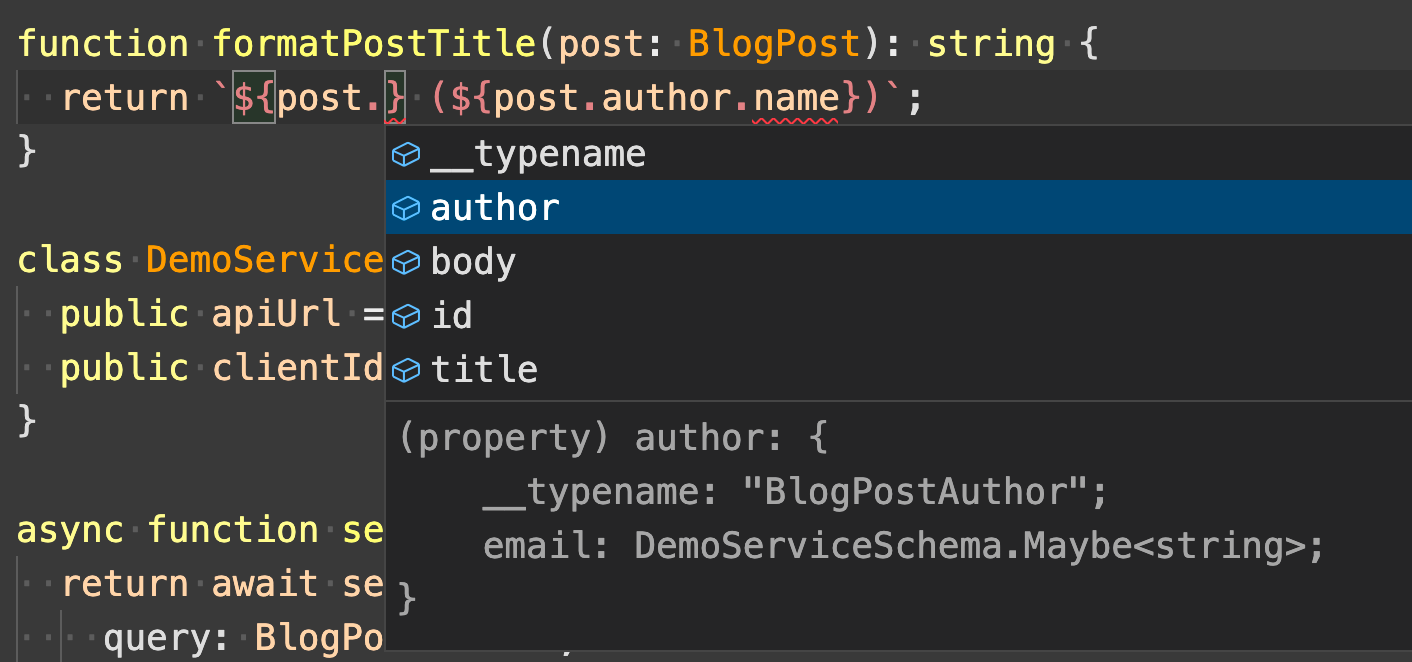

Along with the error prevention benefits that these automatically generated types provide, the types also make for a more approachable and productive developer experience as developers can see exactly what fields are available across the codebase via code completion.
See a walkthrough of these automatically generated types in the recorded talk!
Mirage JS
All the benefits that we have seen so far around being able to decouple and reduce the friction between developing the client and the server are lost if we still have to spin up the service to generate responses during development or testing. One option would be to stub the server’s responses, but given the number of different ways to traverse the GraphQL schema, trying to manually stub the backend responses and then keep those stubbed responses up to date as queries are added and modified becomes burdensome. The solution we use at Salsify is an API mocking library, Mirage. By extending this tool with our own layer of default configuration, we have an easy way to set up Mirage to serve GraphQL requests. By again leaning into our conventions, we can make the out-of-the-box experience “just work” for most of our use cases—lookup-by-id, pagination, basic mutations, and errors all work with little to no configuration as both our server and client are working off the same set of conventions.
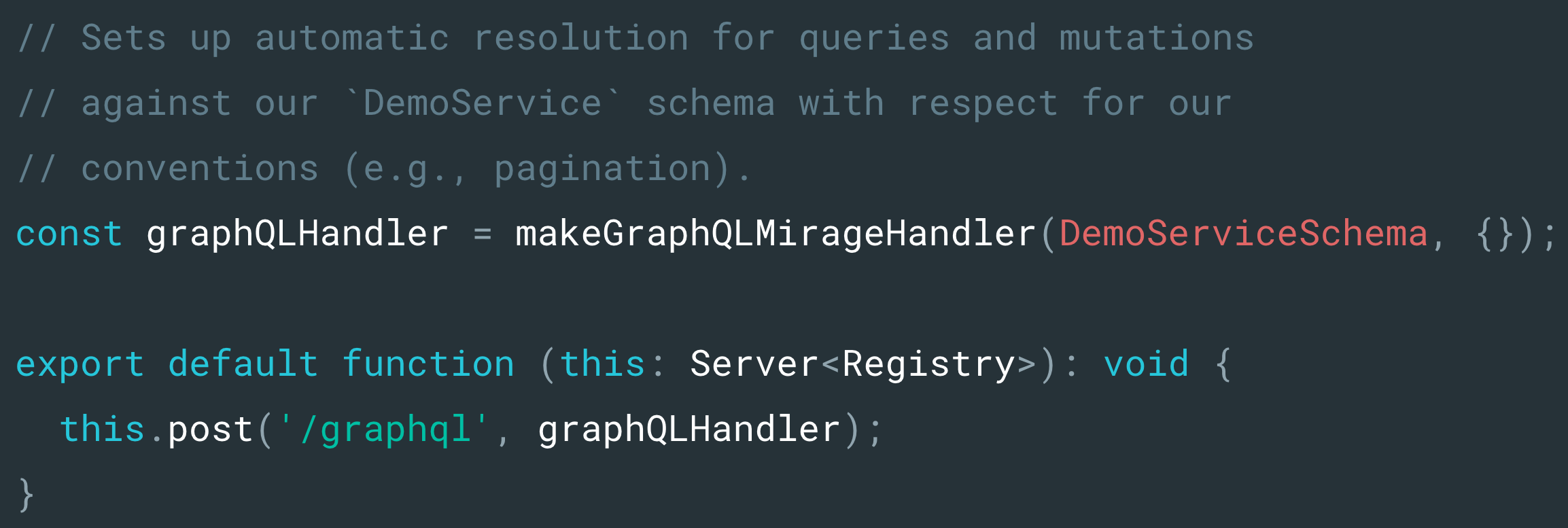

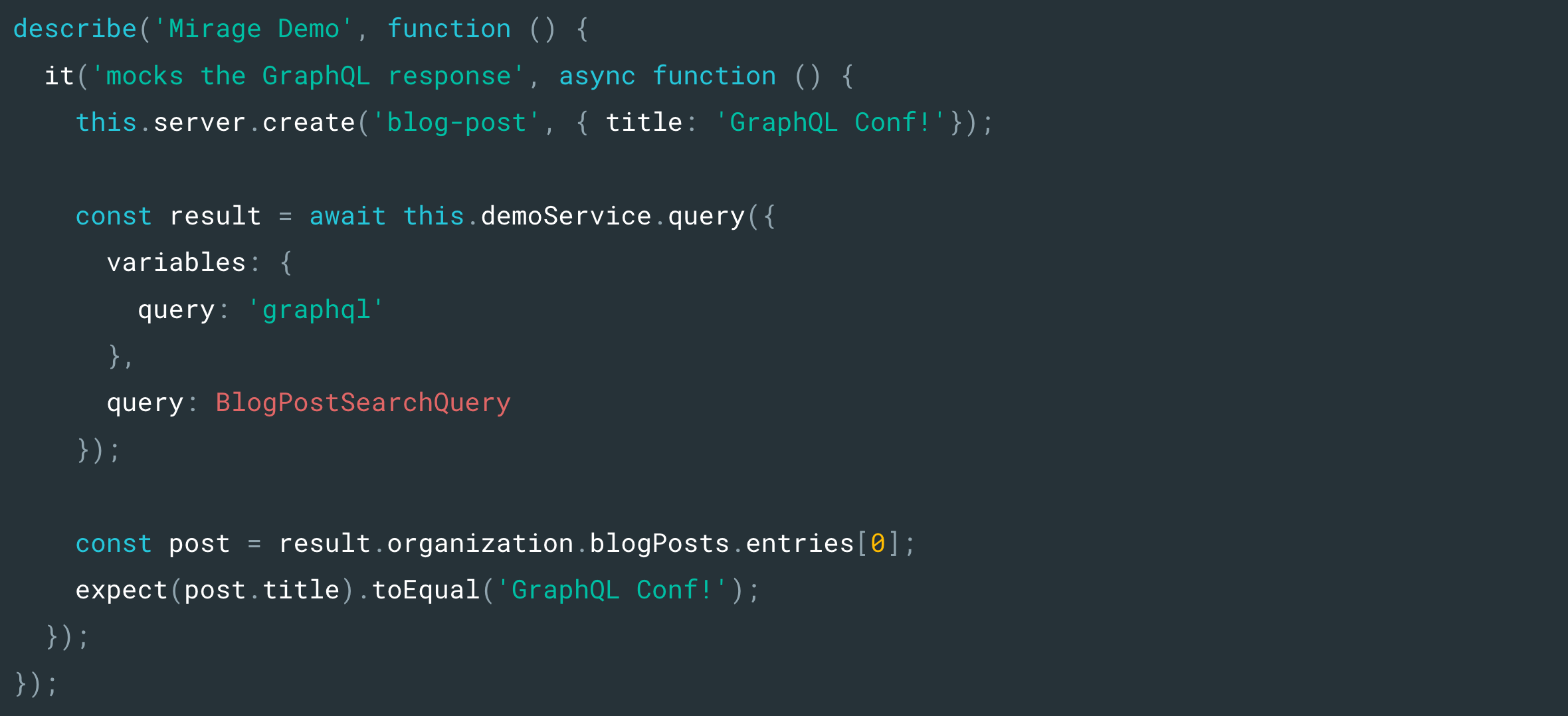
The majority of our Mirage tooling is exposed through our makeGraphQLMirageHandler helper which handles the complexity of parsing and traversing incoming queries, loading records from the Mirage database, and formatting the response correctly. Developers need little configuration to get started, and not needing to reimplement our common conventions further reduces the setup overhead and chance for human error. Once configured, Mirage can intercept GraphQL requests in tests and during development and generate a response for us all without having to worry about stubbing responses making it easier to develop, test, and refactor our code.

Breaking Schema Changes
While automatically generated TypeScript types based on the GraphQL schema help avoid bugs when developers write and modify their queries, there is still the danger that someone could make a breaking change to the schema itself. In this case, the client’s type checking would not flag the issue until the developer pulled the latest version of the schema and regenerated the types.


For example, let’s say we change the BlogPost.author field from non-nullable to nullable. Since the client thinks the author field will always be present, the client assumes it can blindly pull the Author.name without checking for null. This would be a safe assumption since the server would never be able to send a null author with the old schema. However, with the new schema, the client could run into an unexpected type error since the server is no longer bound by that non-null constraint.
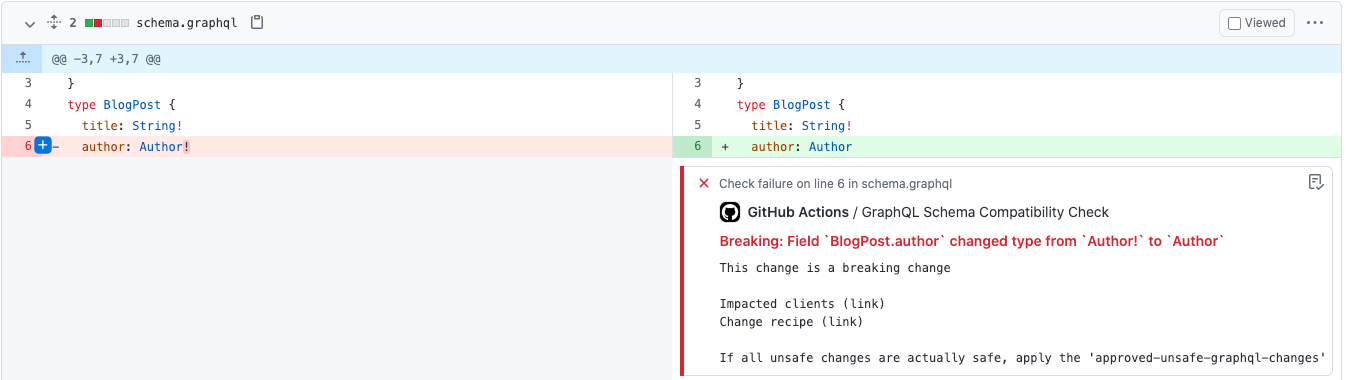

To defend against this danger, we have developed a build-time check for the server that uses the graphql-schema_comparator gem to look for and automatically flag any breaking changes to the GraphQL schema. Instrumentation reports which clients are using which fields, enum values, and arguments, so when we find a breaking change, we can either verify the change is safe because no one is using it or know who we have to alert about the upcoming change. As a result, we have more confidence that we are not breaking clients as we evolve our schema. This breaking-change-check is a good example of how the properties of GraphQL enable tooling that would not otherwise be possible. For example, with a REST endpoint, the server would not know which pieces of the response a client is relying on, so changes to the response are all the more risky. With GraphQL, we know which pieces of the API clients are using down to the individual fields ultimately helping us avoid breaking changes.
Conclusion
That wraps the tools I wanted to show you. I hope I demonstrated how these tools complement each other, allow the power of GraphQL shine through, and create a delightful end-to-end developer experience. Furthermore, I hope there are some concrete ideas here that you can take back to your teams or inspirations for your own tooling. GraphQL enables tooling that isn’t possible with other technologies, so I urge you to lean into that benefit and strive to have tooling do the hard and tedious jobs allowing developers to focus on the fun and impactful things—like building new features. In the end, you will have safer, less-error prone systems and a GraphQL experience that is more approachable, enjoyable, and productive!